검색결과 리스트
Thread에 해당되는 글 3건
- 2022.10.29 스프링 핵심 원리 - 고급편 3
- 2021.05.21 java 8 정리6
- 2021.05.20 java 8 정리5
글
스프링 핵심 원리 - 고급편 3
인프런 강의 62일차.
- 스프링 핵심 원리 - 고급편 (김영한 강사님)
- 반드시 한번은 정복해야할 쉽지 않은 내용들
- 크게 3가지 고급 개념을 학습
1. 스프링 핵심 디자인 패턴
> 템플릿 메소드 패턴
> 전략 패턴
> 템플릿 콜백 패턴
> 프록시 패턴
> 데코레이터 패턴
2. 동시성 문제와 쓰레드 로컬
> 웹 애플리케이션
> 멀티쓰레드
> 동시성 문제
3. 스프링 AOP
> 개념, 용어정리
> 프록시 - JDK 동적 프록시, CGLIB
> 동작 원리
> 실전 예제
> 실무 주의 사항
- 기타
> 스프링 컨테이너의 확장 포인트 - 빈 후처리기
> 스프링 애플리케이션을 개발하는 다양한 실무 팁
- 타입 컨버터, 파일 업로드, 활용, 쿠키, 세션, 필터, 인터셉터, 예외 처리, 타임리프, 메시지, 국제화, 검증 등등
2. 쓰레드 로컬 - ThreadLocal
2.1. 필드 동기화 - 개발
- 앞서 로그 추적기를 만들면서 다음 로그를 출력할 때 트랜잭션ID 와 level 을 동기화 하는 문제가 있었다.
- 이 문제를 해결하기 위해 TraceId 를 파라미터로 넘기도록 구현했다.
- 이렇게 해서 동기화는 성공했지만, 로그를 출력하는 모든 메서드에 TraceId 파라미터를 추가해야 하는 문제가 발생했다.
- TraceId 를 파라미터로 넘기지 않고 이 문제를 해결할 수 있는 방법은 없을까?
> 확장성을 고려한 로그 추적기를 개발해보자
package hello.advanced.trace.logtrace;
import hello.advanced.trace.TraceStatus;
public interface LogTrace {
TraceStatus begin(String message);
void end(TraceStatus status);
void exception(TraceStatus status, Exception e);
}
- hello/advanced/trace/logtrace/LogTrace.java
- 로그 추적기를 위한 최소한의 기능인 begin() , end() , exception() 를 정의했다.
package hello.advanced.trace.logtrace;
import hello.advanced.trace.TraceId;
import hello.advanced.trace.TraceStatus;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class FieldLogTrace implements LogTrace {
private static final String START_PREFIX = "-->";
private static final String COMPLETE_PREFIX = "<--";
private static final String EX_PREFIX = "<X-";
private TraceId traceIdHolder; //traceId 동기화, 동시성 이슈 존재함
@Override
public TraceStatus begin(String message) {
syncTraceId();
TraceId traceId = traceIdHolder;
Long startTimeMs = System.currentTimeMillis();
log.info("[{}] {}{}", traceId.getId(), addSpace(START_PREFIX, traceId.getLevel()), message);
return new TraceStatus(traceId, startTimeMs, message);
}
private void syncTraceId() {
if(traceIdHolder == null){
traceIdHolder = new TraceId();
} else {
traceIdHolder = traceIdHolder.createNextId();
}
}
@Override
public void end(TraceStatus status) {
complete(status, null);
}
@Override
public void exception(TraceStatus status, Exception e) {
complete(status, e);
}
private void complete(TraceStatus status, Exception e) {
Long stopTimeMs = System.currentTimeMillis();
long resultTimeMs = stopTimeMs - status.getStartTimeMs();
TraceId traceId = status.getTraceId();
if (e == null) {
log.info("[{}] {}{} time={}ms", traceId.getId(), addSpace(COMPLETE_PREFIX, traceId.getLevel()), status.getMessage(),
resultTimeMs);
} else {
log.info("[{}] {}{} time={}ms ex={}", traceId.getId(), addSpace(EX_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs,
e.toString());
}
releaseTraceId();
}
private void releaseTraceId() {
if(traceIdHolder.isFirstLevel()){
traceIdHolder = null; //destory
} else {
traceIdHolder = traceIdHolder.createPreviousId();
}
}
private static String addSpace(String prefix, int level) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < level; i++) {
sb.append( (i == level - 1) ? "|" + prefix : "| ");
}
return sb.toString();
}
}
- hello/advanced/trace/logtrace/FieldLogTrace.java
- FieldLogTrace 는 기존에 만들었던 HelloTraceV2 와 거의 같은 기능을 한다. TraceId 를 동기화 하는 부분만 파라미터를 사용하는 것에서 TraceId traceIdHolder 필드를 사용하도록 변경되었다.
- 이제 직전 로그의 TraceId 는 파라미터로 전달되는 것이 아니라 FieldLogTrace 의 필드인 traceIdHolder 에 저장된다.
- 여기서 중요한 부분은 로그를 시작할 때 호출하는 syncTraceId() 와 로그를 종료할 때 호출하는 releaseTraceId() 이다.
- syncTraceId()
> TraceId 를 새로 만들거나 앞선 로그의 TraceId 를 참고해서 동기화하고, level 도 증가한다.
> 최초 호출이면 TraceId 를 새로 만든다.
> 직전 로그가 있으면 해당 로그의 TraceId 를 참고해서 동기화하고, level 도 하나 증가한다.
> 결과를 traceIdHolder 에 보관한다.
- releaseTraceId()
> 메서드를 추가로 호출할 때는 level 이 하나 증가해야 하지만, 메서드 호출이 끝나면 level 이 하나 감소해야 한다.
> releaseTraceId() 는 level 을 하나 감소한다.
> 만약 최초 호출( level==0 )이면 내부에서 관리하는 traceId 를 제거한다.
package hello.advanced.trace.logtrace;
import hello.advanced.trace.TraceStatus;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class FieldLogTraceTest {
FieldLogTrace trace = new FieldLogTrace();
@Test
void begin_end_level2() {
TraceStatus status1 = trace.begin("hello1");
TraceStatus status2 = trace.begin("hello2");
trace.end(status2);
trace.end(status1);
}
@Test
void begin_exception_level2() {
TraceStatus status1 = trace.begin("hello1");
TraceStatus status2 = trace.begin("hello2");
trace.exception(status2, new IllegalStateException());
trace.exception(status1, new IllegalStateException());
}
}- hello/advanced/trace/logtrace/FieldLogTraceTest.java
// begin_end_level2() 실행결과
[71ef1c66] hello1
[71ef1c66] |-->hello2
[71ef1c66] |<--hello2 time=10ms
[71ef1c66] hello1 time=30ms
// begin_exception_level2() 실행결과
[737d1363] hello1
[737d1363] |-->hello2
[737d1363] |<X-hello2 time=1ms ex=java.lang.IllegalStateException
[737d1363] hello1 time=2ms ex=java.lang.IllegalStateException
- 실행 결과를 보면 트랜잭션ID 도 동일하게 나오고, level 을 통한 깊이도 잘 표현된다.
- FieldLogTrace.traceIdHolder 필드를 사용해서 TraceId 가 잘 동기화 되는 것을 확인할 수 있다.
- 이제 불필요하게 TraceId 를 파라미터로 전달하지 않아도 되고, 애플리케이션의 메서드 파라미터도 변경하지 않아도 된다
2.2. 필드 동기화 - 개발
- 지금까지 만든 FieldLogTrace 를 애플리케이션에 적용해보자.
- 우선 FieldLogTrace 를 수동으로 스프링 빈으로 등록하자. 수동으로 등록하면 향후 구현체를 편리하게 변경할 수 있다는 장점이 있다.
- v2 -> v3 복사
package hello.advanced;
import hello.advanced.trace.logtrace.LogTrace;
import hello.advanced.trace.logtrace.FieldLogTrace;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() {
return new FieldLogTrace();
}
}- hello/advanced/LogTraceConfig.java
package hello.advanced.app.v3;
import hello.advanced.trace.TraceStatus;
import hello.advanced.trace.helloTrace.HelloTraceV1;
import hello.advanced.trace.helloTrace.HelloTraceV2;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequiredArgsConstructor
public class OrderControllerV3 {
private final OrderServiceV3 orderService;
private final HelloTraceV2 trace;
@GetMapping("/v3/request")
public String request(String itemId) {
TraceStatus status = null;
try {
status = trace.begin("OrderController.request()");
orderService.OrderItem(status.getTraceId(), itemId);
trace.end(status);
return "ok";
}catch (Exception e){
trace.exception(status, e);
throw e; //예외를 꼭 다시 던져줘야 한다. (trace.exception에서 예외처리를 해두었기 때문)
}
}
}- hello/advanced/app/v3/OrderControllerV3.java
package hello.advanced.app.v3;
import hello.advanced.trace.TraceId;
import hello.advanced.trace.TraceStatus;
import hello.advanced.trace.helloTrace.HelloTraceV2;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
@Service
@RequiredArgsConstructor
public class OrderServiceV3 {
private final OrderRepositoryV3 orderRepository;
private final HelloTraceV2 trace;
public void OrderItem(TraceId traceId, String itemId){
TraceStatus status = null;
try {
status = trace.beginSync(traceId, "OrderService.OrderItem()");
orderRepository.save(status.getTraceId(), itemId);
trace.end(status);
}catch (Exception e){
trace.exception(status, e);
throw e; //예외를 꼭 다시 던져줘야 한다. (trace.exception에서 예외처리를 해두었기 때문)
}
}
}
- hello/advanced/app/v3/OrderServiceV3.java
package hello.advanced.app.v3;
import hello.advanced.trace.TraceId;
import hello.advanced.trace.TraceStatus;
import hello.advanced.trace.helloTrace.HelloTraceV2;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Repository;
@Repository
@RequiredArgsConstructor
public class OrderRepositoryV3 {
private final HelloTraceV2 trace;
public void save(TraceId traceId, String itemId) {
TraceStatus status = null;
try {
status = trace.beginSync(traceId, "OrderRepository.save()");
//저장 로직
if (itemId.equals("ex")) { //상품 ID 가 ex 면 예외 처리
throw new IllegalStateException("예외 발생!");
}
sleep(1000); //상품을 저장하는데 1초가 걸린다고 가정
trace.end(status);
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
private void sleep(int miilis) {
try {
Thread.sleep(miilis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- hello/advanced/app/v3/OrderRepositoryV3.java
// 정상 실행 로그
[73088ff4] OrderController.request()
[73088ff4] |-->OrderService.OrderItem()
[73088ff4] | |-->OrderRepository.save()
[73088ff4] | |<--OrderRepository.save() time=1005ms
[73088ff4] |<--OrderService.OrderItem() time=1005ms
[73088ff4] OrderController.request() time=1007ms
// 에러 실행 로그
[69c22a14] OrderController.request()
[69c22a14] |-->OrderService.OrderItem()
[69c22a14] | |-->OrderRepository.save()
[69c22a14] | |<X-OrderRepository.save() time=0ms ex=java.lang.IllegalStateException: 예외 발생!
[69c22a14] |<X-OrderService.OrderItem() time=1ms ex=java.lang.IllegalStateException: 예외 발생!
[69c22a14] OrderController.request() time=2ms ex=java.lang.IllegalStateException: 예외 발생!
- traceIdHolder 필드를 사용한 덕분에 파라미터 추가 없는 깔끔한 로그 추적기를 완성했다.
2.3. 필드 동기화 - 동시성 문제
- FieldLogTrace 는 싱글톤으로 등록된 스프링 빈이다. 이 객체의 인스턴스가 애플리케이션에 딱 1개 존재한다는 뜻이다.
- 이렇게 하나만 있는 인스턴스의 FieldLogTrace.traceIdHolder 필드를 여러 쓰레드가 동시에 접근하기 때문에 문제가 발생한다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
//테스트에서 lombok 사용
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
}- build.gradle
- test 코드에서 lombok 사용을 위한 dependencies 추가
package hello.advanced.trace.threadlocal.code;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class FieldService {
private String nameStore;
public String logic(String name) {
log.info("저장 name={} -> nameStore={}", name, nameStore);
nameStore = name;
sleep(1000);
log.info("조회 nameStore={}", nameStore);
return nameStore;
}
private void sleep(int miles) {
try {
Thread.sleep(miles);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- hello/advanced/trace/threadlocal/code/FieldService.java
- 파라미터로 넘어온 name 을 필드인 nameStore 에 저장 후 1초간 쉰 다음 필드에 저장된 nameStore 를 반환한다.
package hello.advanced.trace.threadlocal;
import hello.advanced.trace.threadlocal.code.FieldService;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
@Slf4j
public class FieldServiceTest {
private FieldService fieldService = new FieldService();
@Test
void field() {
log.info("main Start");
Runnable userA = () -> {
fieldService.logic("userA");
};
Runnable userB = () -> {
fieldService.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start(); //A실행
sleep(2000); //동시성 문제 발생X
// sleep(100); //동시성 문제 발생O
threadB.start(); //B실행
sleep(3000); //메인 쓰레드 종료 대기
log.info("main end");
}
private void sleep(int miles) {
try {
Thread.sleep(miles);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}- hello/advanced/trace/threadlocal/FieldServiceTest.java
- sleep(2000) 을 설정해서 thread-A 의 실행이 끝나고 나서 thread-B 가 실행되도록 해보자. 참고로 FieldService.logic() 메서드는 내부에 sleep(1000) 으로 1초의 지연이 있다. 따라서 1초 이후에 호출하면 순서대로 실행할 수 있다. 여기서는 넉넉하게 2초 (2000ms)를 설정했다
// sleep(2000) 실행 결과
[Test worker] INFO hello.advanced.trace.threadlocal.FieldServiceTest - main Start
[thread-A] INFO hello.advanced.trace.threadlocal.code.FieldService - 저장 name=userA -> nameStore=null
[thread-A] INFO hello.advanced.trace.threadlocal.code.FieldService - 조회 nameStore=userA
[thread-B] INFO hello.advanced.trace.threadlocal.code.FieldService - 저장 name=userB -> nameStore=userA
[thread-B] INFO hello.advanced.trace.threadlocal.code.FieldService - 조회 nameStore=userB
[Test worker] INFO hello.advanced.trace.threadlocal.FieldServiceTest - main end


- 실행 결과를 보면 문제가 없다.
> Thread-A 는 userA 를 nameStore 에 저장했다.
> Thread-A 는 userA 를 nameStore 에서 조회했다.
> Thread-B 는 userB 를 nameStore 에 저장했다.
> Thread-B 는 userB 를 nameStore 에서 조회했다
* 동시성 문제 발생 코드
- 이번에는 sleep(100) 을 설정해서 thread-A 의 작업이 끝나기 전에 thread-B 가 실행되도록 해보자.
- 참고로 FieldService.logic() 메서드는 내부에 sleep(1000) 으로 1초의 지연이 있다.
- 따라서 1초 이후에 호출하면 순서대로 실행할 수 있다.
- 다음에 설정할 100(ms)는 0.1초이기 때문에 thread-A 의 작업이 끝나기 전에 thread-B 가 실행된다.
// sleep(100) 실행 결과
[Test worker] INFO hello.advanced.trace.threadlocal.FieldServiceTest - main Start
[thread-A] INFO hello.advanced.trace.threadlocal.code.FieldService - 저장 name=userA -> nameStore=null
[thread-B] INFO hello.advanced.trace.threadlocal.code.FieldService - 저장 name=userB -> nameStore=userA
[thread-A] INFO hello.advanced.trace.threadlocal.code.FieldService - 조회 nameStore=userB
[thread-B] INFO hello.advanced.trace.threadlocal.code.FieldService - 조회 nameStore=userB
[Test worker] INFO hello.advanced.trace.threadlocal.FieldServiceTest - main end- 실행 결과를 보면 문제가 있다.
> Thread-A 는 userA 를 nameStore 에 저장했다.
> Thread-B 는 userB 를 nameStore 에 저장했다.
> Thread-A 는 userB 를 nameStore 에서 조회했다.
> Thread-B 는 userB 를 nameStore 에서 조회했다

- 먼저 thread-A 가 userA 값을 nameStore 에 보관한다.

- 0.1초 이후에 thread-B 가 userB 의 값을 nameStore 에 보관한다. 기존에 nameStore 에 보관되어 있던 userA 값은 제거되고 userB 값이 저장된다

- thread-A 의 호출이 끝나면서 nameStore 의 결과를 반환받는데, 이때 nameStore 는 앞의 2번에서 userB 의 값으로 대체되었다. 따라서 기대했던 userA 의 값이 아니라 userB 의 값이 반환된다.
- thread-B 의 호출이 끝나면서 nameStore 의 결과인 userB 를 반환받는다.
* 동시성 문제
- 결과적으로 Thread-A 입장에서는 저장한 데이터와 조회한 데이터가 다른 문제가 발생한다.
- 이처럼 여러 쓰레드가 동시에 같은 인스턴스의 필드 값을 변경하면서 발생하는 문제를 동시성 문제라 한다.
- 이런 동시성 문제는 여러 쓰레드가 같은 인스턴스의 필드에 접근해야 하기 때문에 트래픽이 적은 상황에서는 확률상 잘 나타나지 않고, 트래픽이 점점 많아질 수 록 자주 발생한다.
- 특히 스프링 빈 처럼 싱글톤 객체의 필드를 변경하며 사용할 때 이러한 동시성 문제를 조심해야 한다.
- 이전 회사에서도 발생했었고, 쩔쩔맸던 기억이 난다..
* 해결 방법
- 지금처럼 싱글톤 객체의 필드를 사용하면서 동시성 문제를 해결하려면 어떻게 해야할까? 다시 파라미터를 전달하는 방식으로 돌아가야 할까? 이럴 때 사용하는 것이 바로 쓰레드 로컬이다.
2.4. ThreadLocal - 소개
- 쓰레드 로컬은 해당 쓰레드만 접근할 수 있는 특별한 저장소를 말한다.



- 자바는 언어차원에서 쓰레드 로컬을 지원하기 위한 java.lang.ThreadLocal 클래스를 제공한다.
2.5. ThreadLocal - 소개
- ThreadLocal을 사용해서 구현해보자
package hello.advanced.trace.threadlocal.code;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class ThreadLocalService {
private ThreadLocal<String> nameStore = new ThreadLocal<>();
public String logic(String name) {
log.info("저장 name={} -> nameStore={}", name, nameStore.get());
nameStore.set(name);
sleep(1000);
log.info("조회 nameStore={}", nameStore.get());
return nameStore.get();
}
private void sleep(int miles) {
try {
Thread.sleep(miles);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- hello/advanced/trace/threadlocal/code/ThreadLocalService.java
- 기존에 사용하던 String nameStore 변수를 ThreadLocal<String> 객체로 선언해서 사용한다.
- 객체이기 때문에 get/set/remove을 사용해 조회/저장/제거한다.
> 해당 쓰레드가 쓰레드 로컬을 모두 사용하고 나면 ThreadLocal.remove() 를 호출해서 쓰레드 로컬에 저장된 값을 제거해주어야 한다.
package hello.advanced.trace.threadlocal;
import hello.advanced.trace.threadlocal.code.ThreadLocalService;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
@Slf4j
public class ThreadLocalServiceTest {
private ThreadLocalService service = new ThreadLocalService();
@Test
void field() {
log.info("main Start");
Runnable userA = () -> {
service.logic("userA");
};
Runnable userB = () -> {
service.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start(); //A실행
sleep(2000); //동시성 문제 발생X
//sleep(100); //동시성 문제 발생O
threadB.start(); //B실행
sleep(3000); //메인 쓰레드 종료 대기
log.info("main end");
}
private void sleep(int miles) {
try {
Thread.sleep(miles);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- hello/advanced/trace/threadlocal/ThreadLocalServiceTest.java
// sleep(2000) ThreadLocal 테스트 결과
[Test worker] main Start
[thread-A] 저장 name=userA -> nameStore=null
[thread-A] 조회 nameStore=userA
[thread-B] 저장 name=userB -> nameStore=null
[thread-B] 조회 nameStore=userB
[Test worker] main end
// sleep(100) ThreadLocal 테스트 결과
[Test worker] main Start
[thread-A] 저장 name=userA -> nameStore=null
[thread-B] 저장 name=userB -> nameStore=null
[thread-A] 조회 nameStore=userA
[thread-B] 조회 nameStore=userB
[Test worker] main end
- 동시성문제 발생하던 코드 실행 시 정상적으로 조회됨을 알 수 있다.
2.6. ThreadLocal - 동기화 개발
- FieldLogTrace 에서 발생했던 동시성 문제를 ThreadLocal 로 해결해보자.
- TraceId traceIdHolder 필드를 쓰레드 로컬을 사용하도록 ThreadLocal traceIdHolder 로 변경하면 된다.
package hello.advanced.trace.logtrace;
import hello.advanced.trace.TraceId;
import hello.advanced.trace.TraceStatus;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class ThreadLocalLogTrace implements LogTrace {
private static final String START_PREFIX = "-->";
private static final String COMPLETE_PREFIX = "<--";
private static final String EX_PREFIX = "<X-";
// private TraceId traceIdHolder; //traceId 동기화, 동시성 이슈 존재함
private ThreadLocal<TraceId> traceIdHolder = new ThreadLocal<>();
@Override
public TraceStatus begin(String message) {
syncTraceId();
TraceId traceId = traceIdHolder.get();
Long startTimeMs = System.currentTimeMillis();
log.info("[{}] {}{}", traceId.getId(), addSpace(START_PREFIX, traceId.getLevel()), message);
return new TraceStatus(traceId, startTimeMs, message);
}
private void syncTraceId() {
TraceId traceId = traceIdHolder.get();
if (traceId == null) {
traceIdHolder.set(new TraceId());
} else {
traceIdHolder.set(traceId.createNextId());
}
}
@Override
public void end(TraceStatus status) {
complete(status, null);
}
@Override
public void exception(TraceStatus status, Exception e) {
complete(status, e);
}
private void complete(TraceStatus status, Exception e) {
Long stopTimeMs = System.currentTimeMillis();
long resultTimeMs = stopTimeMs - status.getStartTimeMs();
TraceId traceId = status.getTraceId();
if (e == null) {
log.info("[{}] {}{} time={}ms", traceId.getId(), addSpace(COMPLETE_PREFIX, traceId.getLevel()), status.getMessage(),
resultTimeMs);
} else {
log.info("[{}] {}{} time={}ms ex={}", traceId.getId(), addSpace(EX_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs,
e.toString());
}
releaseTraceId();
}
private void releaseTraceId() {
TraceId traceId = traceIdHolder.get();
if (traceId.isFirstLevel()) {
traceIdHolder.remove();//destroy
} else {
traceIdHolder.set(traceId.createPreviousId());
}
}
private static String addSpace(String prefix, int level) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < level; i++) {
sb.append( (i == level - 1) ? "|" + prefix : "| ");
}
return sb.toString();
}
}
- hello/advanced/trace/logtrace/ThreadLocalLogTrace.java
- traceIdHolder 가 필드에서 ThreadLocal 로 변경되었다.
* ThreadLocal.remove()
- 추가로 쓰레드 로컬을 모두 사용하고 나면 꼭 ThreadLocal.remove() 를 호출해서 쓰레드 로컬에 저장된 값을 제거해주어야 한다.
[3f902f0b] hello1
[3f902f0b] |-->hello2
[3f902f0b] |<--hello2 time=2ms
[3f902f0b] hello1 time=6ms //end() -> releaseTraceId() -> level==0,
ThreadLocal.remove() 호출- 여기서는 releaseTraceId() 를 통해 level 이 점점 낮아져서 2 ->1 -> 0이 되면 로그를 처음 호출한 부분으로 돌아온 것이다.
- 따라서 이 경우 연관된 로그 출력이 끝난 것이다. 이제 더 이상 TraceId 값을 추적하지 않아도 된다.
- 그래서 traceId.isFirstLevel() ( level==0 )인 경우 ThreadLocal.remove()를 호출해서 쓰레드로컬에 저장된 값을 제거해준다.
2.7. ThreadLocal - 동기화 적용
- 스프링 빈 등록을 동시성 문제가 있는 FieldLogTrace 대신에 문제를 해결한 ThreadLocalLogTrace 을 등록하자.
package hello.advanced;
import hello.advanced.trace.logtrace.LogTrace;
import hello.advanced.trace.logtrace.ThreadLocalLogTrace;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() {
//return new FieldLogTrace();
return new ThreadLocalLogTrace();
}
}
- hello/advanced/LogTraceConfig.java
- Logtrace가 interface이므로 사용할 구현체를 return 함으로써 관련된 bean을 사용하는 client 소스는 변경하지 않아도된다
2.8. ThreadLocal - 주의사항
- 쓰레드 로컬의 값을 사용 후 제거하지 않고 그냥 두면 WAS(톰캣)처럼 쓰레드 풀을 사용하는 경우에 심각한 문제가 발생할 수 있다.
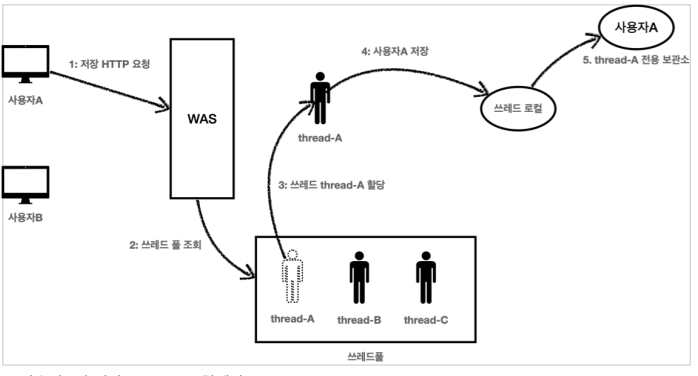
1. 사용자A가 저장 HTTP를 요청했다.
2. WAS는 쓰레드 풀에서 쓰레드를 하나 조회한다.
3. 쓰레드 thread-A 가 할당되었다.
4. thread-A 는 사용자A 의 데이터를 쓰레드 로컬에 저장한다.
5. 쓰레드 로컬의 thread-A 전용 보관소에 사용자A 데이터를 보관한다

1. 사용자A의 HTTP 응답이 끝난다.
2. WAS는 사용이 끝난 thread-A 를 쓰레드 풀에 반환한다. 쓰레드를 생성하는 비용은 비싸기 때문에 쓰레드를 제거하지 않고, 보통 쓰레드 풀을 통해서 쓰레드를 재사용한다.
3. thread-A 는 쓰레드풀에 아직 살아있다. 따라서 쓰레드 로컬의 thread-A 전용 보관소에 사용자A 데이터도 함께 살아있게 된다.

1. 사용자B가 조회를 위한 새로운 HTTP 요청을 한다.
2. WAS는 쓰레드 풀에서 쓰레드를 하나 조회한다.
3. 쓰레드 thread-A 가 할당되었다. (물론 다른 쓰레드가 할당될 수 도 있다.)
4. 이번에는 조회하는 요청이다. thread-A 는 쓰레드 로컬에서 데이터를 조회한다.
5. 쓰레드 로컬은 thread-A 전용 보관소에 있는 사용자A 값을 반환한다.
6. 결과적으로 사용자A 값이 반환된다.
7. 사용자B는 사용자A의 정보를 조회하게 된다.
* 결과적으로 사용자B는 사용자A의 데이터를 확인하게 되는 심각한 문제가 발생하게 된다. 이런 문제를 예방하려면 사용자A의 요청이 끝날 때 쓰레드 로컬의 값을 ThreadLocal.remove() 를 통해서 꼭 제거해야 한다.
'Spring 정리' 카테고리의 다른 글
| 스프링 핵심 원리 - 고급편 5 (0) | 2023.01.25 |
|---|---|
| 스프링 핵심 원리 - 고급편 4 (0) | 2023.01.16 |
| 스프링 핵심 원리 - 고급편 2 (1) | 2022.10.29 |
| 스프링 핵심 원리 - 고급편 1 (1) | 2022.09.20 |
| 스프링 MVC 2편 - 백엔드 웹 개발 활용 기술 21 (0) | 2022.07.25 |
설정
트랙백
댓글
글
java 8 정리6
인프런 강의 8일차.
- 더 자바, Java 8 (백기선 강사님)
1. 자바에서 지원하는 Concurrent 프로그래밍
- 멀티프로세싱 (ProcessBuilder)
- 멀티쓰레드
2. 자바 멀티쓰레드 프로그래밍
- Thread / Runnable
- Thread 상속
public static void main(String[] args){
HelloThread helloThread = new HelloThread();
helloThraed.start();
System.out.println("hello = "+ Thread.currentThread().getName());
}
static class HelloThread extends Thread {
@Override
public void run() {
System.out.println("World = "+ THread.currentThread().getName());
}- Runnable 구현 또는 람다
Thread thread = new Thread(() -> System.out.println("World = "+Thread.currentThread().getName()));
thread.start();
System.out.println("Hello = "+ Thread.currentThread().getName());- 쓰레드 주요 기능
> 현재 쓰레드 멈춰두기(sleep) : 다른 쓰레드가 처리할 수 있도록 기회를 주지만, 그렇다고 락을 놔주진 않는다. (잘못하면 데드락이 걸릴 수 있다)
> 다른 쓰레드 깨우기(interupt) : 다른 쓰레드를 깨워서 interruptedException을 발생 시킨다. 그 에러가 발생했을 때 할 일은 코딩하기 나름. 종료시킬 수도 있고, 계속 하던 일 할 수도 있고, 사용자 구현 가능
> 다른 쓰레드 기다리기(join) : 다른 쓰레드가 끝날 때 까지 기다린다.
package me.whiteship.java8to11;
import ch.qos.logback.core.util.ExecutorServiceUtil;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class App {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
myThread.start();
System.out.println("Hello");
Thread thread = new Thread(() -> {
while(true) {
try {
Thread.sleep(3000L);
} catch (InterruptedException e) {
//InterruptedException은 누군가 이 쓰레드를 깨울 때 동작한다.
System.out.println("Interrupted!!");
return;
}
}
});
thread.start();
System.out.println("Thread : " + Thread.currentThread().getName());
//Thread.sleep(3000L);
//thread.interrupt(); 쓰레드 인터럽트 발생
thread.join(); //위 쓰레드가 끝날 때 까지 기다린다.
System.out.println(thread + " is finished"); //join()으로 인해 위 쓰레드 종료될 때 가지 기다린 후 출력됨
//join으로 다른 쓰레드 기다리는 와중에 또 다른 쓰레드에서 인터럽트 발생 시 복잡도가 기하급수적으로 늘어난다
//여러개의 쓰레드를 코딩으로 관리하는 것은 비효율적 & 어렵기 때문에 executor가 나왔다.
}
static class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread : " + Thread.currentThread().getName());
}
}
}
3. Executors
- 고수준(High-Level) Cuncurency 프로그래밍
> 쓰레드를 만들과 관리하는 작업을 애플리케이션에서 분리
> 그런 기능을 Executors에게 위임
- Executors가 하는 일
> 쓰레드 만들기 : 애플리케이션이 사용할 쓰레드 풀을 만들어서 관리한다.
> 쓰레드 관리 : 쓰레드 생명 주기를 관리한다
> 작업 처리 및 실행 : 쓰레드로 실행할 작업을 제공할 수 있는 API를 제공한다.
- 주요 인터페이스
> Executor: execute(Runnable)
> ExecutorService : Executor 상속 받은 인터페이스로, Callable도 실행할 수 있으며, Executor를 종료시키거나, 여러 Callable을 동시에 실행하는 등의 기능을 제공한다.
> ScheduledExecutorService : ExecutorService를 상속 받은 인터페이스로 특정 시간 이후에 또는 주기적으로 작업을 실행할 수 있다.
- ExecutorService로 작업 실행하기
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> {
System.out.println("Hello = " + Thread.currentThread().getName());
}
- ExecutorService로 멈추기
executorService.shutdown(); //처리중인 작업 기다렸다가 종료
executorService.shutdownNow(); //당장 종료
- Fork/Join 프레임워크
> ExecutorService의 구현체로 손쉽게 멀티 프로세서를 활용할 수 있게끔 도와준다.
package me.whiteship.java8to11;
import java.sql.SQLOutput;
import java.util.concurrent.*;
public class App {
public static void main(String[] args) throws InterruptedException {
/*ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> { //executorService는 만들어서 실행하게 되면 다음 작업이 들어올 때 까지 계속 대기하므로 명시적으로 shutdown을 해주어야 한다.
System.out.println("Thread : "+Thread.currentThread().getName());
});*/
//쓰레드는 2개지만 5개의 작업 실행
ExecutorService executorService = Executors.newFixedThreadPool(2);
//2개의 쓰레드가 나눠서 5개의 작업을 수행한다.
executorService.submit(getRunnable("Hello"));
executorService.submit(getRunnable("World"));
executorService.submit(getRunnable("dhpark"));
executorService.submit(getRunnable("Java"));
executorService.submit(getRunnable("Thread"));
executorService.shutdown(); //graceful shutdown이라고 한다. (현재 진행중인 작업을 전부 마치고 종료)
//executorService.shutdownNow(); //현재 돌고 있는 쓰레드 종료여부와 상관없이 바로 종료*/
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
scheduledExecutorService.schedule(getRunnable("Hello"), 3, TimeUnit.SECONDS); //3초 정도 딜레이 후 getRunnable 실행
scheduledExecutorService.scheduleAtFixedRate(getRunnable("fixedHello"), 1, 2. TimeUnit.SECONDS); //1초만 기다렸다가 2초에 한번씩 출력
}
private static Runnable getRunnable(String message){
return () -> System.out.println(message + Thread.currentThread().getName());
}
}
'Java 정리' 카테고리의 다른 글
| java 8 정리8 (0) | 2021.06.02 |
|---|---|
| java 8 정리7 (0) | 2021.05.26 |
| java 8 정리5 (0) | 2021.05.20 |
| java 8 정리4 (0) | 2021.05.19 |
| java 8 정리3 (0) | 2021.05.17 |
설정
트랙백
댓글
글
java 8 정리5
인프런 강의 7일차.
- 더 자바, Java 8 (백기선 강사님)
1. CompletableFuture 1
- 자바에서 비동기(Asynchronous) 프로그래밍을 가능하게하는 인터페이스.
> Future를 사용해서도 어느정도 가능했지만 하기 힘든 일들이 많았다.
- Future로는 하기 어렵던 작업들
> Future를 외부에서 완료 시킬 수 없다. 취소하거나, get()에 타임아웃을 설정할 수는 있다.
> 블로킹 코드(get())을 사용하지 않고서는 작업이 끝났을 때 콜백을 실행할 수 없다.
> 여러 Future를 조합할 수 없다. ex) Event 정보 가져온 다음 Event에 참석하는 회원의 목록 가져오기
> 예외 처리용 API를 제공하지 않는다.
- CompletableFuture
> Implements Future
> Impletments CompletableFuture
- 비동기로 작업 실행하기
> 리턴값이 없는 경우 : runAsync()
> 리턴값이 있는 경우 : supplySync()
> 원하는 Executor(쓰레드풀)를 사용해서 실행할 수도 있다.(기본은 ForkJoinPool.commonPool())
- 콜백 제공하기
> thenApply(Function) : 리턴값을 받아서 다른 값으로 바꾸는 콜백
> thenAccept(Consumer) : 리턴값을 또 다른 작업으로 처리하는 콜백 (리턴없이)
> thenRun(Runnable) : 리턴값을 받아 다른 작업을 처리하는 콜백
> 콜백 자체를 또 다른 쓰레드에서 실행할 수 있다.
- 조합하기
> thenCompose() : 두 작업이 서로 이어서 실행하도록 조합
> thenCombine() : 두 작업을 독립적으로 실행하고, 둘 다 종료했을 때 콜백 실행
> allOf() : 여러 작업을 모두 실행하고 모든 작업 결과에 콜백 실행
> anyOf() : 여러 작업 중 가장 빨리 끝난 하나의 결과에 콜백 실행
- 예외처리
> exceptionally(Function) : exception 발생 시 처리하는 코드
> handle(BiFunction) : handle은 예외가 발생했을 때, 발생하지 않았을 때 둘 다 사용가능하다
package me.whiteship.java8to11;
import ch.qos.logback.core.util.ExecutorServiceUtil;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;
import java.util.stream.Collectors;
public class App {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(4);
Future<String> future = executorService.submit(() -> "hello");
future.get(); //get이 블로킹 코드이니 get 이후에 콜백 로직이 들어와야한다.
//Case1. 명시적으로 dhpark 값 세팅해서 선언
CompletableFuture<String> completableFuture = new CompletableFuture<>();
completableFuture.complete("dhpark"); //completablefuture의 기본 값을 dhpark으로 정의
System.out.println(completableFuture.get()); //dhpark 출력
//Case2. static factory method 사용
CompletableFuture<String> completableFuture1 = CompletableFuture.completedFuture("dhpark");
System.out.println(completableFuture1.get()); //dhpark 출력
//리턴이 없는 작업은 runAsync 사용
CompletableFuture<Void> completableFuture2 = CompletableFuture.runAsync(() -> {
System.out.println("Hello " + Thread.currentThread().getName()); //future만 정의했기 때문에 수행되지 않고, join()이나 get()을 해야 동작한다.
});
System.out.println(completableFuture2.get());
//리턴이 있는 경우 supplyAsync 사용
CompletableFuture<String> completableFuture3 = CompletableFuture.supplyAsync(() -> {
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
});
System.out.println(completableFuture3.get());
//위의 예제들은 Future로도 구현 가능한 기능이라고 봐도 무방하다.
//CompletableFuture는 추가로 callback 구현이 가능.
//리턴이 있는 supplyAsync에 callback구현(thenApply)
CompletableFuture<String> completableFuture4 = CompletableFuture.supplyAsync(() -> {
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
}).thenApply((s) -> { //java5때의 Future로는 get 호출하기 이전에 콜백 정의가 불가능했다.
System.out.println(Thread.currentThread().getName());
return s.toUpperCase();
});
System.out.println(completableFuture4.get()); //get을 호출하지 않으면 아무 일이 일어나지 않는건 동일함
//리턴이 없는 콜백의 경우 thenAccept
CompletableFuture<Void> completableFuture5 = CompletableFuture.supplyAsync(() -> {
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
}).thenAccept((s) -> { //java5때의 Future로는 get 호출하기 이전에 콜백 정의가 불가능했다.
System.out.println(Thread.currentThread().getName());
System.out.println(s.toUpperCase());
});
completableFuture5.get(); //get을 호출하지 않으면 아무 일이 일어나지 않는건 동일함
//전달되는 파라미터(리턴) 없이 동작을 하기만 하면 되는 것은 thenRun
//별다른 Executor 정의가 없다면 ForkJoinPool.commonPool을 사용하게 된다.
//ForkJoinPool : Java7에 도입된 기능, Executor를 구현한 구현체. 작업을 DeQueue를 사용해서 자기 쓰레드가 할일이 없으면 할일을 가져와서 처리하는 방식
//자기가 파생시키는 subTask들을 다른 쓰레드에 분산시켜서 작업을 처리하고, 결과를 모아서 최종 결과값을 도출해냄
//원할 경우 Executor를 새로 정의하는 것도 가능하다.
//새로 정의한 경우 supplyAsync의 2번째 인자로 전달해야한다.
ExecutorService executorService1 = Executors.newFixedThreadPool(4);
CompletableFuture<Void> completableFuture6 = CompletableFuture.supplyAsync(() -> {
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
}, executorService1).thenRun(() -> { //새로 정의한 executorService를 사용해서 쓰레드 호출
//ExecutorService를 추가 하지 않은 경우 Hello ForkJoinPool.commonPool-worker 출력
//ExecutorService를 추가한 경우 Hello pool-1-thread-1 출력
//java5때의 Future로는 get 호출하기 이전에 콜백 정의가 불가능했다.
System.out.println(Thread.currentThread().getName());
});
//}, executorService1); //callback에서도 정의된 executor를 사용할 수 있다. 이 때 callback은 @async를 사용해야 한다. thenRunAsync, thenApplyAsync, ...
//다만 supplyAsync때 사용된 쓰레드와 callback에서 사용된 쓰레드가 다를 수 있다!
//쓰레드 조합해서 사용하기
//thenCompose
CompletableFuture<String> hello = CompletableFuture.supplyAsync(() -> {
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
});
//Case1. 2개의 쓰레드 작업 조합
CompletableFuture<String> completableFuture7 = hello.thenCompose(App::getWorld);
System.out.println(completableFuture7.get()); //Hello World 출력
CompletableFuture<String> world = CompletableFuture.supplyAsync(() -> {
System.out.println("World" + Thread.currentThread().getName());
return "World";
});
//Case2. 입력 값은 2개, 결과 값은 1개로 처리
CompletableFuture<String> completableFuture8 = hello.thenCombine(world, (h, w) -> h + " " + w); //BiFunction에 해당하는 람다 실행
System.out.println(completableFuture8.get()); //hello world 출력
//Case3. 2개 이상의 태스크를 합쳐서 한번에 실행
//인자로 넘어가는 태스크의 결과가 동일한 타입인지 보장할 수 없고, 태스크가 전부 성공한다는 보장도 없기에 결과가 무의미하다.
CompletableFuture<Void> voidCompletableFuture = CompletableFuture.allOf(hello, world)
.thenAccept(System.out::println); //thenAccept가 실행되어서 null이 출력됨
System.out.println(voidCompletableFuture.get()); //결과가 null이다.
//Case3의 결과가 null이기에 해당 결과를 출력시킬 수 있는 방법은 Collection으로 모아서 한데 처리해야한다.
List<CompletableFuture<String>> completableFutures = Arrays.asList(hello, world);
CompletableFuture[] futuresArray = completableFutures.toArray(new CompletableFuture[completableFutures.size()]);
CompletableFuture<List<String>> listCompletableFuture = CompletableFuture.allOf(futuresArray)
.thenApply(v -> { //결과인 v는 무의미하고, return이 중요하다.
return completableFutures.stream()
//thenApply가 호출되는 시점은 futuresArray의 모든 작업이 끝난 상태이다!
//CompletableFuture.get()을 써도 되나 get은 checkedException이 발생하므로 exception까지 정의해줘야 가능함.
.map(CompletableFuture::join) //join은 uncheckedException이 발생
.collect(Collectors.toList());
});
listCompletableFuture.get().forEach(System.out::println); //Hello \n World 출력됨
//Case4. 아무거나 빨리 끝나는거 결과 하나 받아서 실행
CompletableFuture<Void> voidCompletableFuture1 = CompletableFuture.anyOf(hello, world).thenAccept(System.out::println);
voidCompletableFuture1.get(); //hello랑 world중에 먼저 끝나는 작업 출력
//Case5. Exception 처리
boolean throwError = true;
CompletableFuture<String> exceptionHello = CompletableFuture.supplyAsync(() -> {
if (throwError) {
throw new IllegalStateException();
}
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
}).exceptionally(ex -> { //에러 발생 시 수행하는 코드
System.out.println(ex);
return "Error!";
});
//Case6. handle은 예외가 발생했을 때, 발생하지 않았을 때 둘 다 사용가능하다 (BiFunction)
CompletableFuture<String> exceptionHello1 = CompletableFuture.supplyAsync(() -> {
if (throwError) {
throw new IllegalStateException();
}
System.out.println("Hello " + Thread.currentThread().getName());
return "Hello";
}).handle((result, ex) -> {
if(ex != null){
System.out.println(ex);
return "Error!";
}
return result; //에러가 없으면 결과 리턴
});
}
private static CompletableFuture<String> getWorld(String message) {
return CompletableFuture.supplyAsync(() -> {
System.out.println("World " + Thread.currentThread().getName());
return message + "World";
});
}
}'Java 정리' 카테고리의 다른 글
| java 8 정리7 (0) | 2021.05.26 |
|---|---|
| java 8 정리6 (0) | 2021.05.21 |
| java 8 정리4 (0) | 2021.05.19 |
| java 8 정리3 (0) | 2021.05.17 |
| java 8 정리2 (0) | 2021.05.13 |
