검색결과 리스트
Tensorflow 정리에 해당되는 글 4건
- 2021.07.20 base64 서명 데이터 학습
- 2021.06.29 머신러닝 모델 배포 방법
- 2021.06.08 SVM 알고리즘
글
base64 서명 데이터 학습
1. Base64 인코딩 된 것 이미지로 전환해서 학습이 가능한지 확인.
- base64 데이터 형태로 학습이 가능하다.
2. base64 데이터 학습 사용법 (Keras 모델의 Xception 사용)
- tensorflow가 아직 익숙하지 않음로 Keras를 사용하여 구현.
2.1 keras 모델 학습을 위한 전제조건
from tensorflow import keras
model = keras.applications.Xception(weights="imagenet")
model.compile(loss="categorical_crossentropy")2.2 작업 순서
- 1. base64 문자열로 인코딩된 입력 이미지 디코딩
- 2. Tensor로 변환
- 3. 크기 조정
- 4. 모델에 필요한 영상 전처리 단계 적용
from typing import Callable, Tuple
import tensorflow as tf
# if using tf >=2.0, disable eager execution to use tf.placeholder
tf.compat.v1.disable_eager_execution()
class ServingInputReceiver:
"""
A callable object that returns a
`tf.estimator.export.ServingInputReceiver`
object that provides a method to convert
`image_bytes` input to model.input
"""
def __init__(
self, img_size: Tuple[int],
preprocess_fn: Callable = None,
input_name: str = "input_1"):
self.img_size = img_size
self.preprocess_fn = preprocess_fn
self.input_name = input_name
def decode_img_bytes(self, img_b64: str) -> tf.Tensor:
"""
Decodes a base64 encoded bytes and converts it to a Tensor.
Args:
img_bytes (str): base64 encoded bytes of an image file
Returns:
img (Tensor): a tensor of shape (width, height, 3)
"""
img = tf.io.decode_image(
img_b64,
channels=3,
dtype=tf.uint8,
expand_animations=False
)
img = tf.image.resize(img, size=self.img_size)
img = tf.ensure_shape(img, (*self.img_size, 3))
img = tf.cast(img, tf.float32)
return img
def __call__(self) -> tf.estimator.export.ServingInputReceiver:
# a placeholder for a batch of base64 string encoded of image bytes
imgs_b64 = tf.compat.v1.placeholder(
shape=(None,),
dtype=tf.string,
name="image_bytes")
# apply self.decode_img_bytes() to a batch of image bytes (imgs_b64)
imgs = tf.map_fn(
self.decode_img_bytes,
imgs_b64,
dtype=tf.float32)
# apply preprocess_fn if applicable
if self.preprocess_fn:
imgs = self.preprocess_fn(imgs)
return tf.estimator.export.ServingInputReceiver(
features={self.input_name: imgs},
receiver_tensors={"image_bytes": imgs_b64}
)2.3 객체 생성
- base64 input을 처리할 serving_input_receiver객체 생성
- 객체 생성 후 리사이즈 & 모델 적용 (keras.applications.xception.preprocess_input)
from tensorflow import keras
serving_input_receiver = ServingInputReceiver(
img_size=(299, 299),
preprocess_fn=keras.applications.xception.preprocess_input,
input_name="input_1")2.4 TF 서비스 모델 export
estimator_save_dir = "estimators/xception"
estimator = tf.keras.estimator.model_to_estimator(
keras_model=model,
model_dir=estimator_save_dir)
export_model_dir = "models/classification/xception/" # this is where the exported model will end up.
estimator.export_saved_model(
export_dir_base=export_model_dir,
serving_input_receiver_fn=serving_input_receiver)- 2.4 까지 적용했을 때의 Keras 모델 구조
models
└── classification
└── xception
└── 1586063263
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index2.5 export한 모델 서비스하기
- Docker 이용
docker run -p 8500:8500 \
-p 8501:8501 \
-v <path_to_model_dir>/models/classification/xception:/models/xception \
-e MODEL_NAME=xception -t tensorflow/serving2.6 서비스한 모델 테스트
- 샘플 예제
import base64
from typing import Dict
import requests
SERVER_URL = "http://localhost:8501/v1/models/xception:predict"
def encode_img(img_filename: str) -> str:
with open(img_filename, "rb") as f:
img_bytes = base64.b64encode(f.read())
return img_bytes.decode("utf8")
def prepare_request(img_filename: str) -> Dict:
img_bytes = encode_img(img_filename)
req = {
"instances": [
{"image_bytes": {"b64": img_bytes}},
]
}
return req
def send_request(img_filename: str) -> Dict:
predict_request = prepare_request(img_filename)
response = requests.post(SERVER_URL, json=predict_request)
response.raise_for_status()
return response.json()- 샘플 예제 request 방법(파일 경로 및 확장자)
response = send_request("path-to-img.jpg|png|gif")- 샘플 예제 output
{'predictions': [[0.000263870839,
0.000306949107,
0.000248591678,
0.000319328334,
0.000141894678,
0.000295011501,
0.000241611619,
...]]
}
3. 이미지 처리를 위한 다른 사용법
- base64 형태가 아닌 img 로딩해서 사용
3.1 이미지(local file) -> 예측
#이미지를 불러와서 모델 예측에 사용
fpath="image.jpg"
image_size = (224, 224)
img = tf.keras.preprocessing.image.load_img(
fpath,
grayscale=False,
color_mode="rgb",
target_size=IMAGE_SIZE,
interpolation='bilinear')
input_array = tf.keras.preprocessing.image.img_to_array(img)
input_array[0][0] # output: array([167., 103., 66.], dtype=float32)
pred = model_loaded.predict(np.expand_dims(input_array, axis = 0)/255)3.2 이미지(local file) -> base64변환 -> 예측
#이미지를 base64로 읽어와서 예측에 사용
fpath="image.jpg"
# convert image base64 to be sent
image_base64 = base64.b64encode(open(fpath, 'rb').read()).decode("utf-8")
data = json.dumps({'image': image_base64})
# on the server side I get `data` and I want to read the base64 to feed tensorflow model
image = base64.b64decode(json.loads(data)['image'])
image[0:5] # output: b'xffxd8xffxe0x00'
image = tf.io.decode_image(image, channels=3)
image = tf.image.resize(image,
method="bilinear",
size=IMAGE_SIZE)
input_array = np.array(image)
input_array[0][0] # output array([163.3482 , 102.01786 , 62.383926], dtype=float32)
pred = model.predict(np.expand_dims(input_array, axis=0))3.3 이미지(url) -> base64변환 -> 예측 소스는 추가 필요
# Download the image
IMAGE_URL = https://tensorflow.org/images/blogs/serving/cat.jpg
dl_request= requests.get(IMAGE_URL, stream=True)
dl_request.raise_for_status()
# Compose a JSON Predict request (send JPEG image in base64).
jpeg_bytes= base64.b64encode(dl_request.content).decode('utf-8')
predict_request= '{"instances" : [{"b64": "%s"}]}' % jpeg_bytes
#output : {"instances" : [{"b64": "/9j/4AAQSkZJRgABAQAASABIAAD/4QBYRXhpZgAATU0AKgAAKACiiigAooooAKKKKACiiigAooooA//Z"}]}
4. 1회성이 아닌 지속적 학습하기 위해 어떻게 구현해야 하는가?
- 단순히 생각하기로는 학습 서버와 운영 서버를 따로 구성
- 학습 서버는 입력된 base64 input에 대해 지속적으로 학습 수행
- 학습 후 일정 주기마자 운영 서버에 배포
- 머신러닝모델 학습배포 사이클 https://ichi.pro/ko/meosin-leoning-model-eul-peulodeogsyeon-e-baepohaneun-munje-245001997032627
5. 참고 json
#2. base64 데이터 표현 json
{ "b64": "base64 encoded string" }
#3. base64 데이터 표현 json(서명 정의 및 캡션 포함)
{ "signature_name": "classify_objects",
"examples":
[
{
"image": { "b64": "aW1hZ2UgYnl0ZXM=" },
"caption": "seaside"
},
{
"image": { "b64": "YXdlc29tZSBpbWFnZSBieXRlcw==" },
"caption": "mountains"
}
]
}
6. 기존에 논의되었던 문장기준 한글 OCR 판별 참고자료
http://101.101.175.217:8080/static/aiocr/learning
https://medium.com/@sdanaipat/deploy-keras-models-using-tensorflow-serving-5b46b7d5e024
'Tensorflow 정리' 카테고리의 다른 글
| 머신러닝 모델 배포 방법 (0) | 2021.06.29 |
|---|---|
| SVM 알고리즘 (0) | 2021.06.08 |
| TensorFlow 연습 (0) | 2021.05.19 |
설정
트랙백
댓글
글
머신러닝 모델 배포 방법
머신러닝 모델 개발은 사용자 서비스를 위한 것.

위 파이프라인 중 '모델 서비스' 단계가 실제 서비스 환경에서 의사결정에 사용될 수 있도록 배치하는 것.
MNIST 데이터 학습을 예시로 들어보면 유저가 8을 손으로 그려서 서버로 보내면 서버에서 훈련된 모델이 해당 인풋을 숫자 8로 인식하여 아웃풋으로 내보내는 것.

모델 서비스란?
머신 러닝 모델을 배포하는 것은 단순히 머신 러닝 모델을 통합하고 입력을 받아 출력을 반환 할 수있는 기존 프로덕션 환경 (1)에 통합하는 것을 의미합니다. 모델을 배포하는 목적은 훈련 된 ML 모델에서 예측을 사용자, 관리 또는 기타 시스템에 관계없이 다른 사람이 사용할 수 있도록하는 것입니다. 모델 배포는 미리 정의 된 목표를 달성하기 위해 시스템 내 소프트웨어 구성 요소의 배열 및 상호 작용을 나타내는 ML 시스템 아키텍처와 밀접한 관련이 있습니다.
모델을 배포하기 전에 머신 러닝 모델이 배포 준비를 마치기 전에 달성해야하는 몇 가지 기준이 있습니다.
- 이식성 : 이것은 한 기계 또는 시스템에서 다른 기계 또는 시스템으로 소프트웨어를 전송할 수있는 능력을 나타냅니다. 휴대용 모델은 응답 시간이 비교적 짧고 최소한의 노력으로 다시 작성할 수있는 모델입니다.
- 확장 성 : 모델을 확장 할 수있는 크기를 나타냅니다. 확장 가능한 모델은 성능을 유지하기 위해 재 설계 할 필요가없는 모델입니다.
ML 모델을 배포하는 일반적인 방법에는 일회성, 배치 및 실시간의 세 가지가 있습니다.
일회성
배포하기 위해 머신 러닝 모델을 지속적으로 학습해야하는 것은 아닙니다. 때로는 모델이 한 번 또는 주기적으로 만 필요합니다. 이 경우 모델은 필요할 때 임시로 교육을 받고 일부 수정이 필요할 때까지 성능이 저하 될 때까지 생산에 투입 될 수 있습니다.
일괄
배치 학습을 사용하면 모델의 최신 버전을 지속적으로 유지할 수 있습니다. 한 번에 데이터의 하위 샘플을 가져 오는 확장 가능한 방법이므로 각 업데이트에 대해 전체 데이터 세트를 사용할 필요가 없습니다. 이는 모델을 일관되게 사용하는 경우 유용하지만 반드시 실시간 예측이 필요하지는 않습니다.
실시간
예를 들어 거래가 사기인지 아닌지를 판단하기 위해 실시간 예측을 원할 경우도 있습니다. 이것은 확률 적 경사 하강 법을 사용한 선형 회귀와 같은 온라인 머신 러닝 모델을 사용하여 가능합니다.
배포 방법을 결정할 때 고려할 요소
ML 모델을 배포하는 방법을 결정할 때 고려해야 할 여러 가지 요인과 의미가 있습니다. 이러한 요소에는 다음이 포함됩니다.
- 예측이 생성되는 빈도와 결과가 얼마나 긴급한지
- 예측을 개별적으로 또는 일괄 적으로 생성해야하는 경우
- 모델의 대기 시간 요구 사항, 보유한 컴퓨팅 성능 및 원하는 서비스 수준 협약(SLA)
- 모델을 배포하고 유지하는 데 필요한 운영상의 영향과 비용
TF Serving
텐서플로우는 모델 서빙을 위한 서버를 따로 제공하고 있다.
- Tensorflow serving server
tensorflow serving server는 tfx(tensorflow extended)의 한 컴포넌트이며 다음과 같은 기능을 제공한다.
- 다양한 프레임워크 지원
- 동시 서빙
- 배치 단위의 서빙
- 모델 관리
- gpu 스케쥴링
- http/grpc 프로토콜
- metric
tfx를 이용한 ML 파이프라인에서는 학습 컴포넌트에서 학습이 된 모델을 tfx Pusher를 통해 클라우드 스토리지, 디렉토리에 전송하면, 서빙서버가 자동으로 추가된 모델을 읽고 로드하여 서빙에 사용하는 방식입니다. 아래 그림을 보면 스토리지가 모델 저장소 역할을 하면서, 모델 버전 관리 기능이 필요하게 됩니다. 한 모델이 학습하며 새로운 체크포인트를 내놓으면, TF Serving은 현재 최고 성능의 모델을 배포하면서 바로 이전 모델로 롤백을 할 준비를 하게 됩니다.

TF Serving은 GPU를 지원하기에 GPU를 사용하니 배치 단위의 요청을 처리할 수 있다는 특징이 있습니다. 물론 요청이 오자마자 바로 GPU로 보내 처리하는게 빠를수도 있으나, 그럴거면 CPU를 사용하는게 나을수도 있습니다. 또 요청을 바로바로 처리하면 처리량 자체가 낮아지는 문제가 있죠. 비싼 GPU 장비의 성능을 뽑고 싶은 것도 있고요.
응답속도는 약간 느려지지만 처리량을 올리기 위해 배치 단위의 서빙을 하기도 합니다. 요청이 실시간으로 들어오면 일정 시간, 요청 수 만큼 기다렸다 조건이 충족할 때 GPU로 보내는 방법이죠.

추가적으로..
머신러닝은 보통 python 혹은 R로 학습된 모델이 많다.
배포하고 싶은 시스템이 해당 언어를 사용하지 않을 경우 어떻게 배포해야할까?
학습 서버에서 API를 구현하고, 이용하고자 하는 서버에서는 해당 API를 호출하여 사용
Python : Flask, Django, Falcon, Hug, ...
R : Plumber
'Tensorflow 정리' 카테고리의 다른 글
| base64 서명 데이터 학습 (0) | 2021.07.20 |
|---|---|
| SVM 알고리즘 (0) | 2021.06.08 |
| TensorFlow 연습 (0) | 2021.05.19 |
설정
트랙백
댓글
글
SVM 알고리즘
서포트 벡터 머신(support vector machine, SVM)은 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다.
그래서 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 된다.
결국 이 결정 경계라는 걸 어떻게 정의하고 계산하는지 이해하는 게 중요하다는 뜻이다.
일단 예시를 보자.
만약 데이터에 2개 속성(feature)만 있다면 결정 경계는 이렇게 간단한 선 형태가 될 거다.

그러나 속성이 3개로 늘어난다면 이렇게 3차원으로 그려야 한다.

그리고 이 때의 결정 경계는 ‘선’이 아닌 ‘평면’이 된다.
우리가 이렇게 시각적으로 인지할 수 있는 범위는 딱 3차원까지다. 차원, 즉 속성의 개수가 늘어날수록 당연히 복잡해질 거다. 결정 경계도 단순한 평면이 아닌 고차원이 될 텐데 이를 “초평면(hyperplane)”이라고 부른다. (어렵게 생각할 필요는 없다. 일단 용어만 알고 넘어가자.)
최적의 결정 경계(Decision Boundary)
결정 경계는 무수히 많이 그을 수 있을 거다. 어떤 경계가 좋은 경계일까?
일단 아래 그림들을 보자.

어떤 그래프가 제일 위태로워 보이는가?
C를 보면 선이 파란색 부류와 너무 가까워서 아슬아슬해보인다.
그렇다면 어떤 결정 경계가 가장 적절해보이는가?
당연히 F다. 두 클래스(분류) 사이에서 거리가 가장 멀기 때문이다.
이제 결정 경계는 데이터 군으로부터 최대한 멀리 떨어지는 게 좋다는 걸 알았다. 실제로 서포트 벡터 머신(Support Vector Machine)이라는 이름에서 Support Vectors는 결정 경계와 가까이 있는 데이터 포인트들을 의미한다. 이 데이터들이 경계를 정의하는 결정적인 역할을 하는 셈이다.
이어서 마진(Margin)이라는 용어에 대해 알아보자.
마진(Margin)
마진(Margin)은 결정 경계와 서포트 벡터 사이의 거리를 의미한다.
아래 그림을 보면 바로 이해된다.
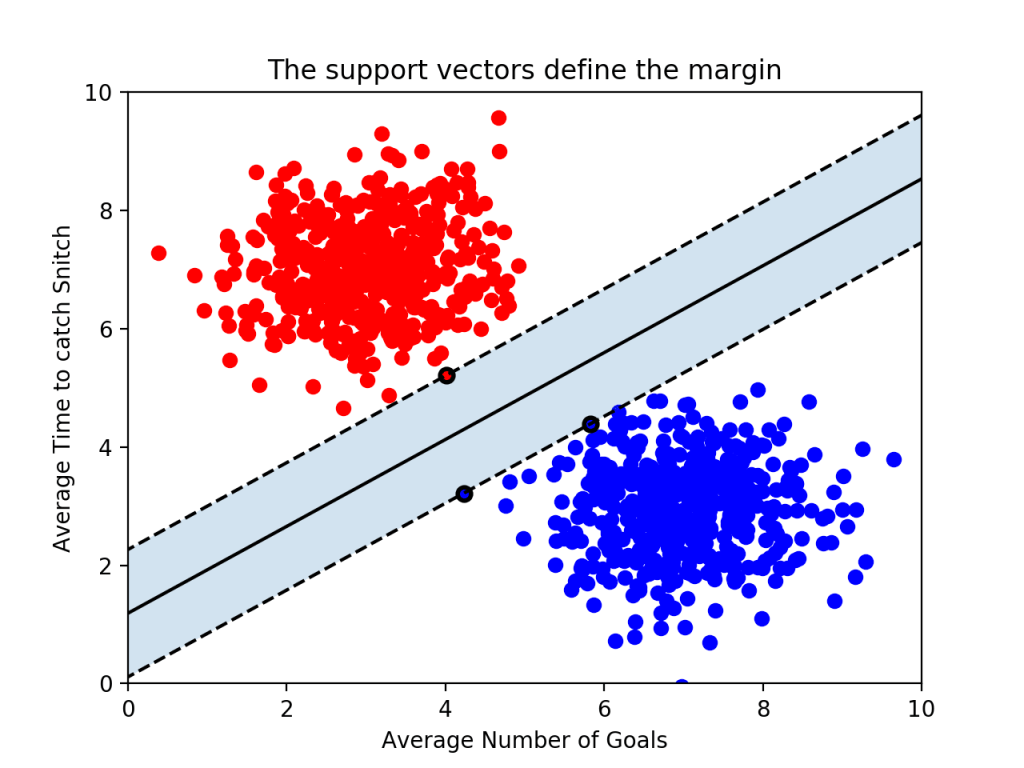
가운데 실선이 하나 그어져있는데, 이게 바로 ‘결정 경계’가 되겠다. 그리고 그 실선으로부터 검은 테두리가 있는 빨간점 1개, 파란점 2개까지 영역을 두고 점선을 그어놓았다. 점선으로부터 결정 경계까지의 거리가 바로 ‘마진(margin)’이다.
여기서 일단 결론을 하나 얻을 수 있다. 최적의 결정 경계는 마진을 최대화한다.
그리고 위 그림에서는 x축과 y축 2개의 속성을 가진 데이터로 결정 경계를 그었는데, 총 3개의 데이터 포인트(서포트 벡터)가 필요했다. 즉, n개의 속성을 가진 데이터에는 최소 n+1개의 서포트 벡터가 존재한다는 걸 알 수 있다.
이번엔 SVM 알고리즘의 장점을 하나 알 수 있다.
대부분의 머신러닝 지도 학습 알고리즘은 학습 데이터 모두를 사용하여 모델을 학습한다. 그런데 SVM에서는 결정 경계를 정의하는 게 결국 서포트 벡터이기 때문에 데이터 포인트 중에서 서포트 벡터만 잘 골라내면 나머지 쓸 데 없는 수많은 데이터 포인트들을 무시할 수 있다. 그래서 매우 빠르다.
이상치(Outlier)를 얼마나 허용할 것인가
SVM은 데이터 포인트들을 올바르게 분리하면서 마진의 크기를 최대화해야 하는데, 결국 이상치(outlier)를 잘 다루는 게 중요하다.
아래 그림을 보자. 선을 살펴보기에 앞서 왼쪽에 혼자 튀어 있는 파란 점과, 오른쪽에 혼자 튀어 있는 빨간 점이 있다는 걸 봐두자. 누가 봐도 아웃라이어다.
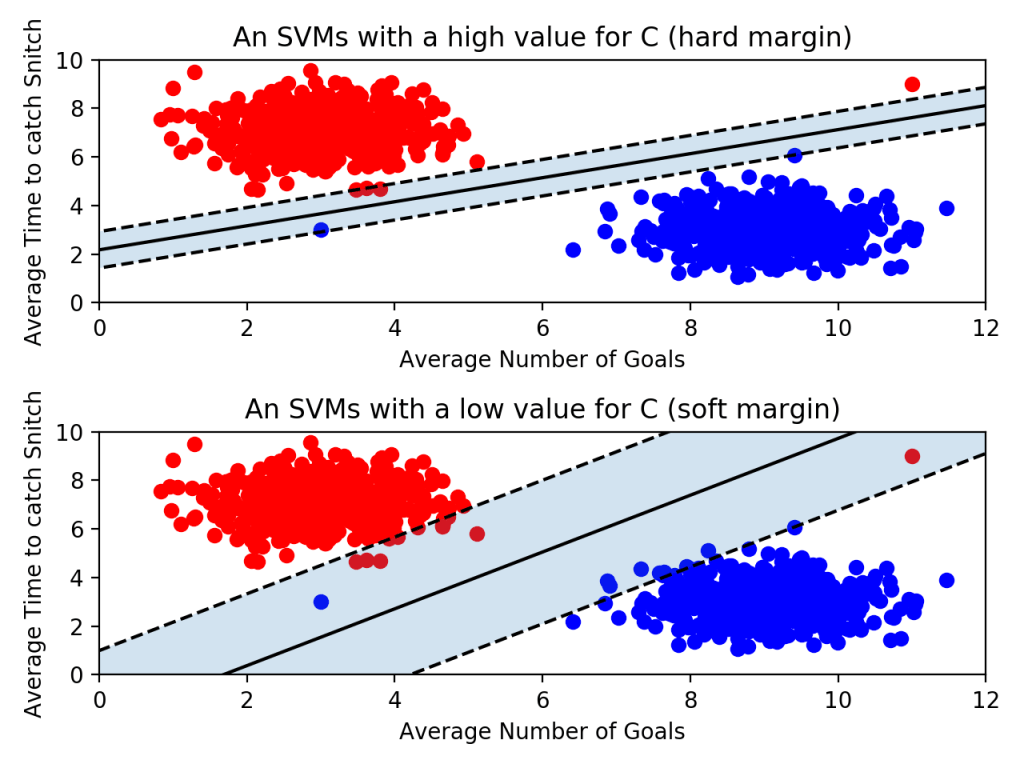
이제 위 아래 그림을 좀 더 자세히 비교해보자.
- 위의 그림은 아웃라이어를 허용하지 않고 기준을 까다롭게 세운 모양이다. 이걸 하드 마진(hard margin)이라고 부른다. 그리고 서포트 벡터와 결정 경계 사이의 거리가 매우 좁다. 즉, 마진이 매우 작아진다. 이렇게 개별적인 학습 데이터들을 다 놓치지 않으려고 아웃라이어를 허용하지 않는 기준으로 결정 경계를 정해버리면 오버피팅(overfitting) 문제가 발생할 수 있다.
- 아래 그림은 아웃라이어들이 마진 안에 어느정도 포함되도록 너그럽게 기준을 잡았다. 이걸 소프트 마진(soft margin)이라고 부른다. 이렇게 너그럽게 잡아 놓으니 서포트 벡터와 결정 경계 사이의 거리가 멀어졌다. 즉, 마진이 커진다. 대신 너무 대충대충 학습하는 꼴이라 언더피팅(underfitting) 문제가 발생할 수 있다.
커널(Kernel)
지금까지는 선형으로 결정 경계를 그을 수 있는 형태의 데이터 세트를 예시로 들었다. 그런데 만약 SVM이 선형으로 분리 할 수 없는 데이터 세트가 있다면 어떻게 해야 할까?
극단적인 예를 들어… 이런 데이터가 있다고 해보자.

빨간색 점을 파란색 점과 분리하는 직선을 그릴 수가 없다..!
위에서 다룬 내용을 가볍게 요약하면 아래와 같다.
- SVM은 분류에 사용되는 지도학습 머신러닝 모델이다.
- SVM은 서포트 벡터(support vectors)를 사용해서 결정 경계(Decision Boundary)를 정의하고, 분류되지 않은 점을 해당 결정 경계와 비교해서 분류한다.
- 서포트 벡터(support vectors)는 결정 경계에 가장 가까운 각 클래스의 점들이다.
- 서포트 벡터와 결정 경계 사이의 거리를 마진(margin)이라고 한다.
- SVM은 허용 가능한 오류 범위 내에서 가능한 최대 마진을 만들려고 한다.
- 파라미터 C는 허용되는 오류 양을 조절한다. C 값이 클수록 오류를 덜 허용하며 이를 하드 마진(hard margin)이라 부른다. 반대로 C 값이 작을수록 오류를 더 많이 허용해서 소프트 마진(soft margin)을 만든다.
- SVM에서는 선형으로 분리할 수 없는 점들을 분류하기 위해 커널(kernel)을 사용한다.
- 커널(kernel)은 원래 가지고 있는 데이터를 더 높은 차원의 데이터로 변환한다. 2차원의 점으로 나타낼 수 있는 데이터를 다항식(polynomial) 커널은 3차원으로, RBF 커널은 점을 무한한 차원으로 변환한다.
SVM은 다음과 같은 현실 세계의 문제들을 해결하는데 사용된다:
- SVM은 텍스트와 하이퍼텍스트를 분류하는데 있어서, 학습 데이터를 상당히 줄일 수 있게 해준다.
- 이미지를 분류하는 작업에서 SVM을 사용할 수 있다. SVM이 기존의 쿼리 개량 구조보다 상당히 높은 검색 정확도를 보인 것에 대한 실험 결과가 있다.
- SVM은 분류된 화합물에서 단백질을 90%까지 구분하는 의학 분야에 유용하게 사용된다.
- SVM을 통해서 손글씨의 특징을 인지할 수 있다.
*코랩 테스트
https://colab.research.google.com/drive/1q3GGhRpjJAoSLTalkhIS-i5cxW2p9pus#scrollTo=Vr_crhIkDcZW
'Tensorflow 정리' 카테고리의 다른 글
| base64 서명 데이터 학습 (0) | 2021.07.20 |
|---|---|
| 머신러닝 모델 배포 방법 (0) | 2021.06.29 |
| TensorFlow 연습 (0) | 2021.05.19 |
